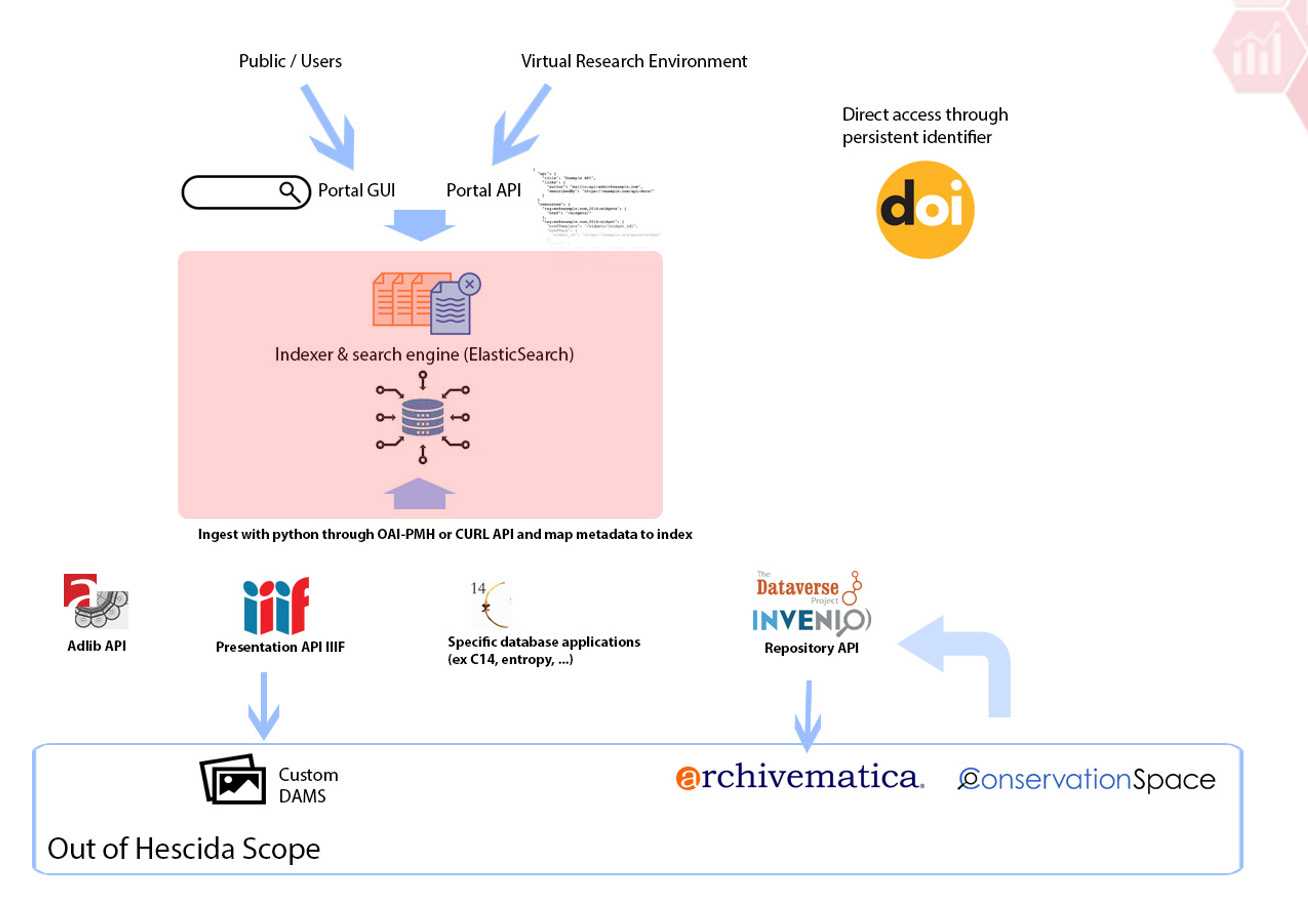
For a long time, relational databases have served us well, but due to the nature of our goals with HESCIDA, they no longer fulfill our needs.
The solution lies within the use of an ‘Indexer’, which in our case will be ElasticSearch. All of our metadata from various datasources will need to be converted to JSON documents and imported into ElasticSearch.
This will allow us following advantages :
Allows us to store very different types of meta-data and search across all of it
Better performance than traditional databases
Scaling as needed is possible due to the cluster nature of the framework
Complex queries and nearly instant refinement options
Being able to add full-text documents as data to be searched on