Why?
At KIK-IRPA we have an exceptionally large collection of images, ranging from official photos taken by our photographers to microscopic imagery/x-rays/cross-sections/…
All these images are in one way, or another linked to an intervention file, but up until now we only had a method for linking the official photographer images to our collection. Thus, a system was needed to gather and document our images.
The DAMS is still a work in progress, but a lot of it is already in a functional state and it will soon go into a testing phase with staff.
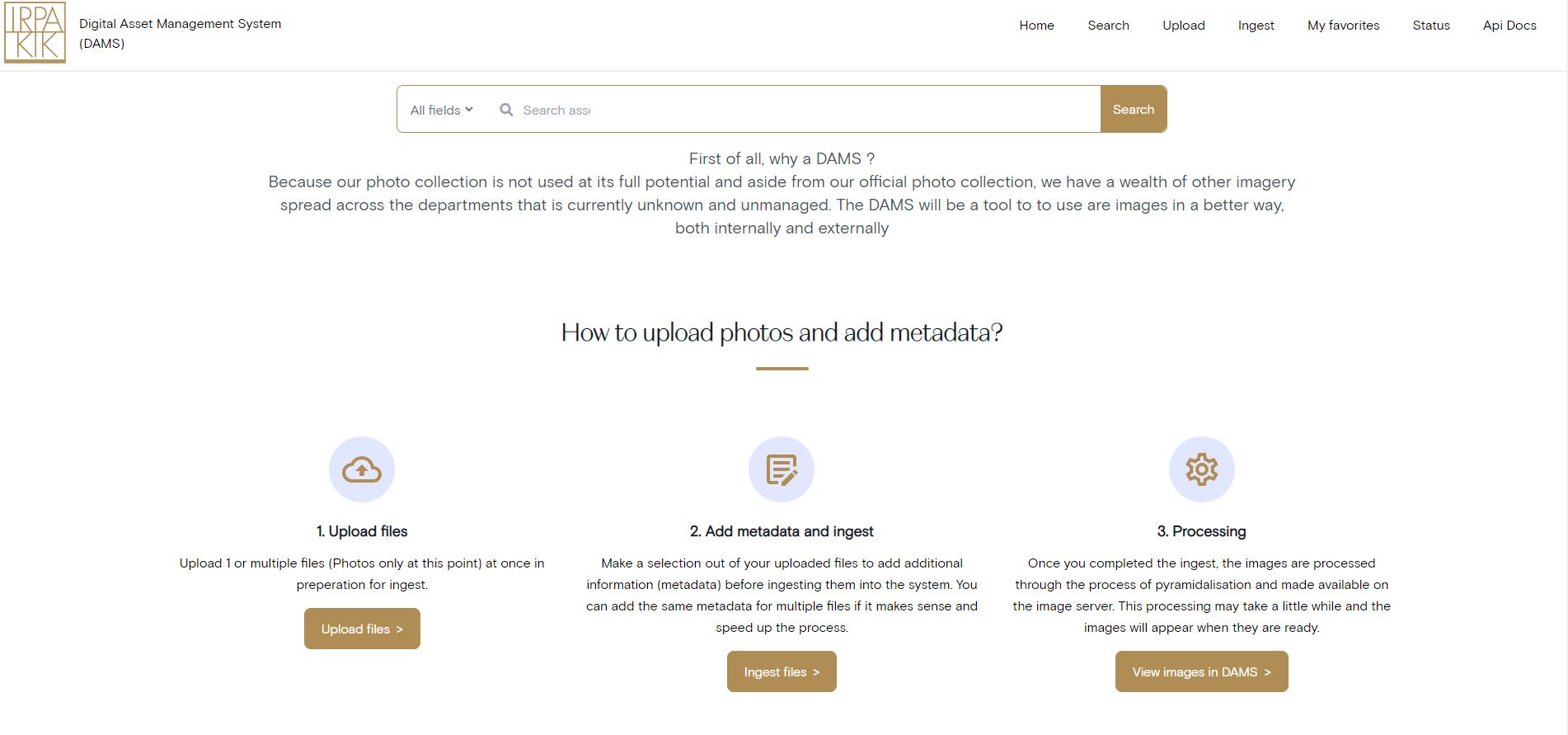
Ingest images
One of the big reasons why we made a DAMS ourselves, was to integrate existing workflows and systems. Our photography department already has a fixed workflow for their images and for that reason, ingestion of those images does not require manual interaction and is fully automated. Images created by other departments, however, can be manually uploaded/ingested and added to the DAMS.
Gradually, the more images are added, this will allow us to search on an intervention file number and get all the images related to the intervention from all departments.
We have also had a IIIF server operational for a few years, so we wanted to re-use our current infrastructure as best as possible, which is why the DAMS does not implement an image server of its own but integrates with the existing infrastructure and transfers images to the IIIF infrastructure after converting and renaming the ingested images.
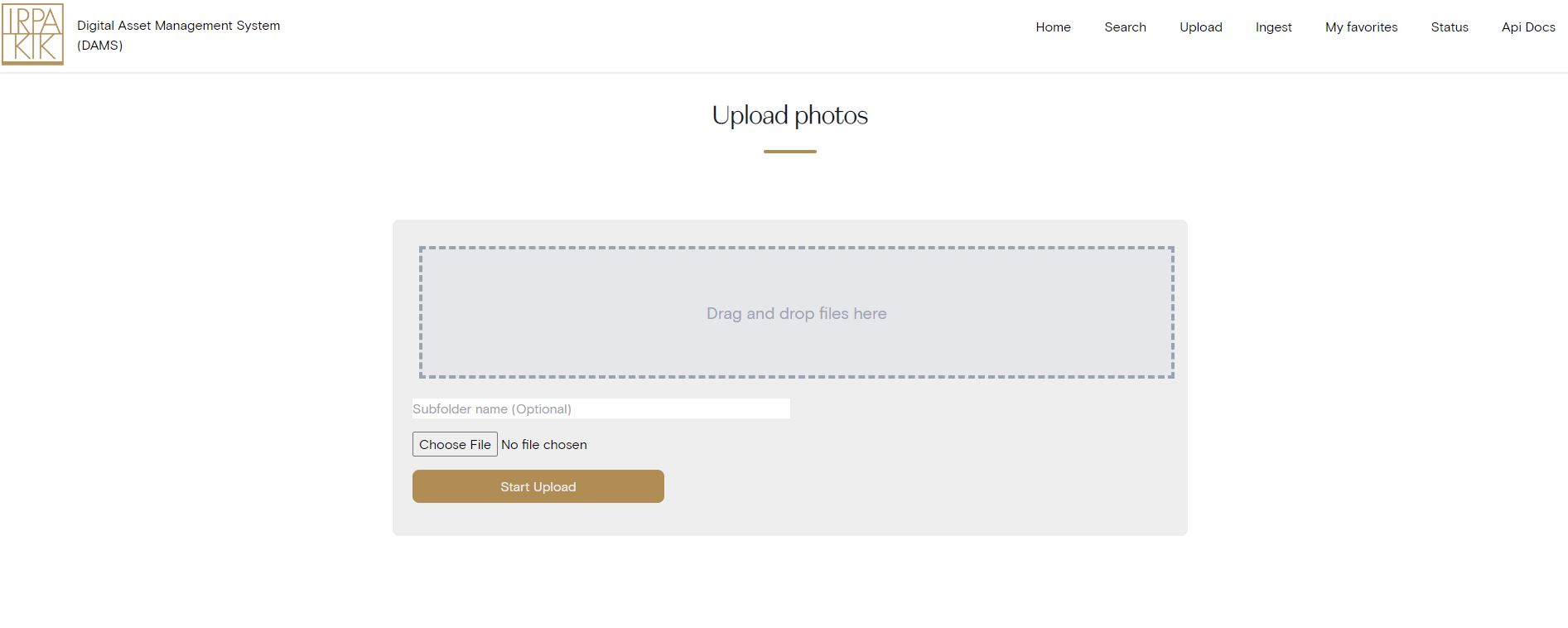
Meta-data
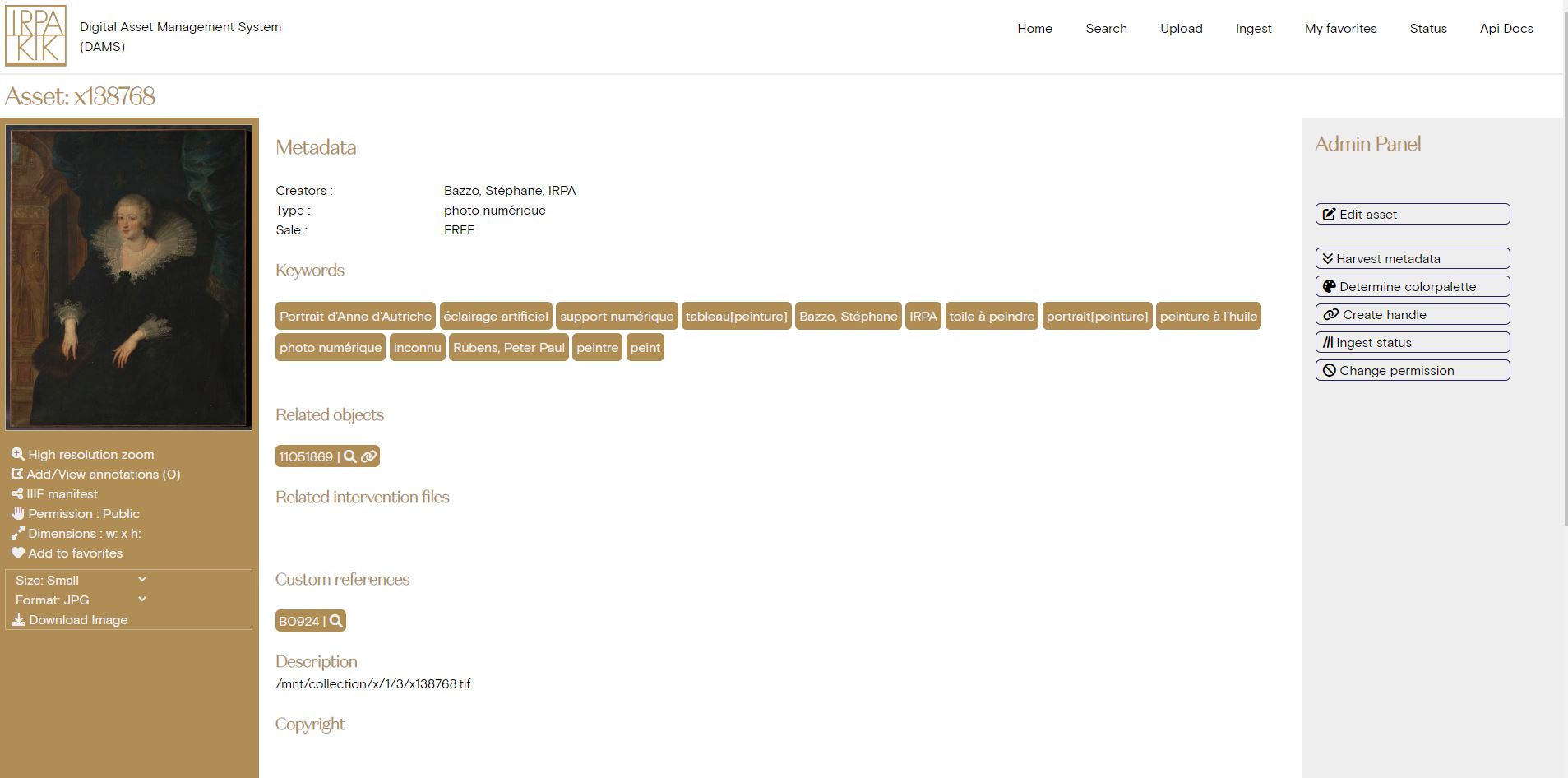
For some of our images (the official ones made by the photographers), meta-data already exists in our collection system, but for most other images, there is none available in a structured system.
This is why the DAMS has 2 types of meta-data, harvested meta-data and custom meta-data. The harvested meta-data can never be changed by a user and is automatically added by the DAMS itself by querying the API of our collection system for information. Users can, however, add meta-data of their own to any asset. Due to the mixed nature of all assets in the DAMS, it is difficult to find/use a fixed vocabulary for meta-data. To at least help and reduce the problem of small variations on meta-data terms and inconsistency, the DAMS will index all meta-data terms currently being used regularly and create a list of terms to be used as suggestions while a user is typing, to guide them towards the use of an already existing meta-data term.
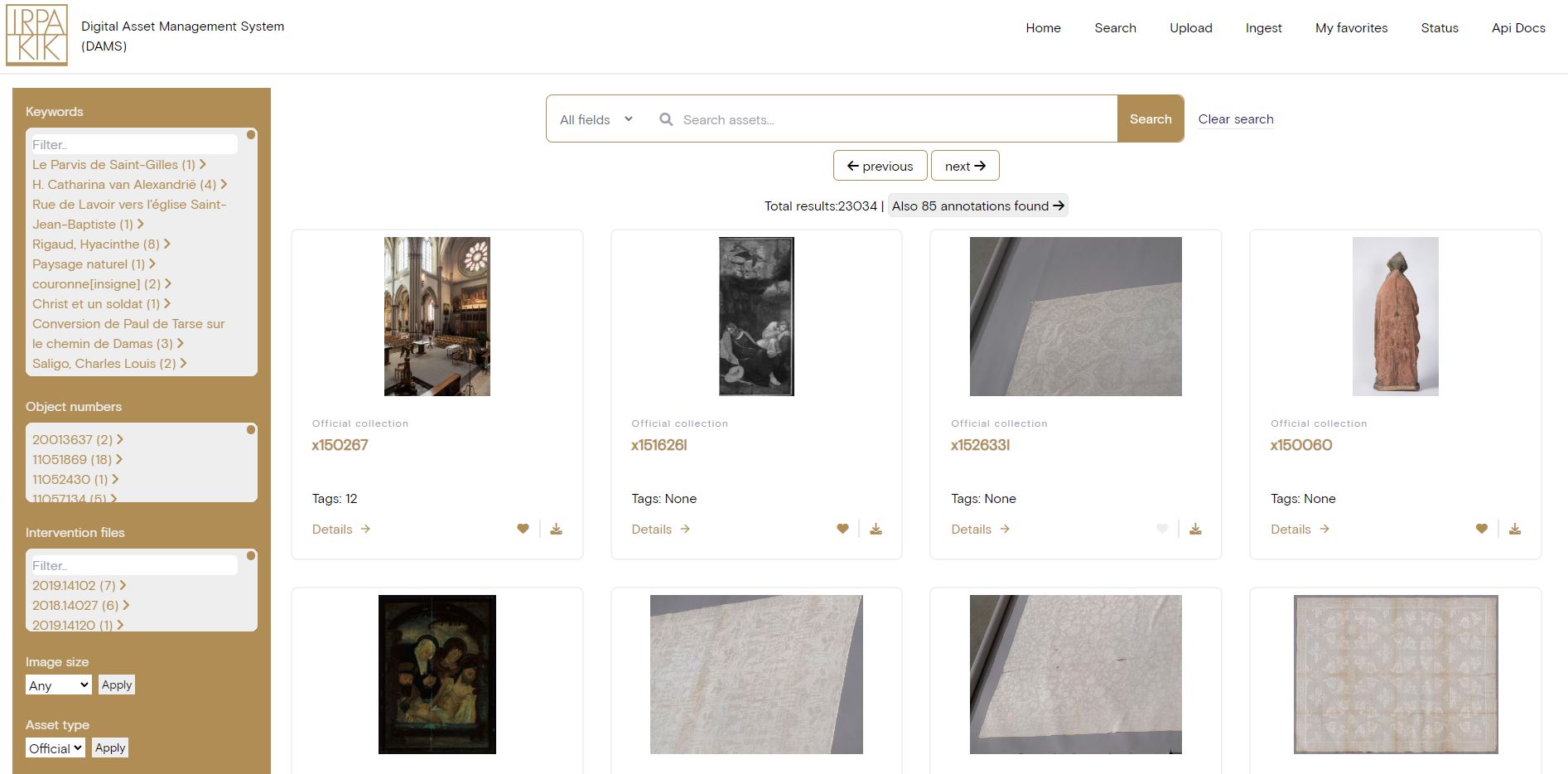
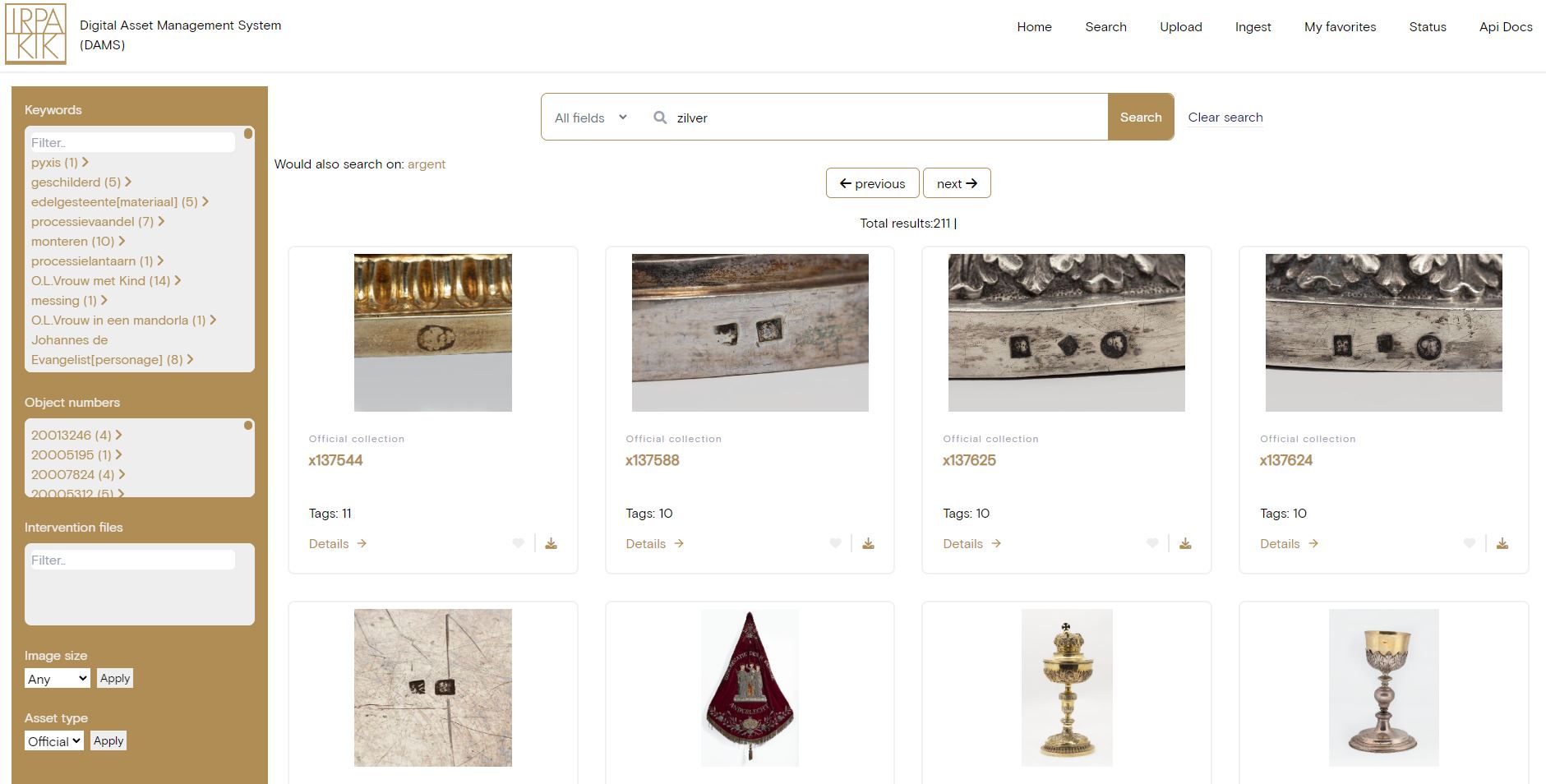
Searching
The DAMS allows for searching in all assets/images with a simple search field that searches on every type of data field. Refinement options are suggested, and it is able to use a synonyms list on query time to handle our multi-language meta-data. One of the latest additions is that it not only searches on asset information, but also on annotations added to these assets.
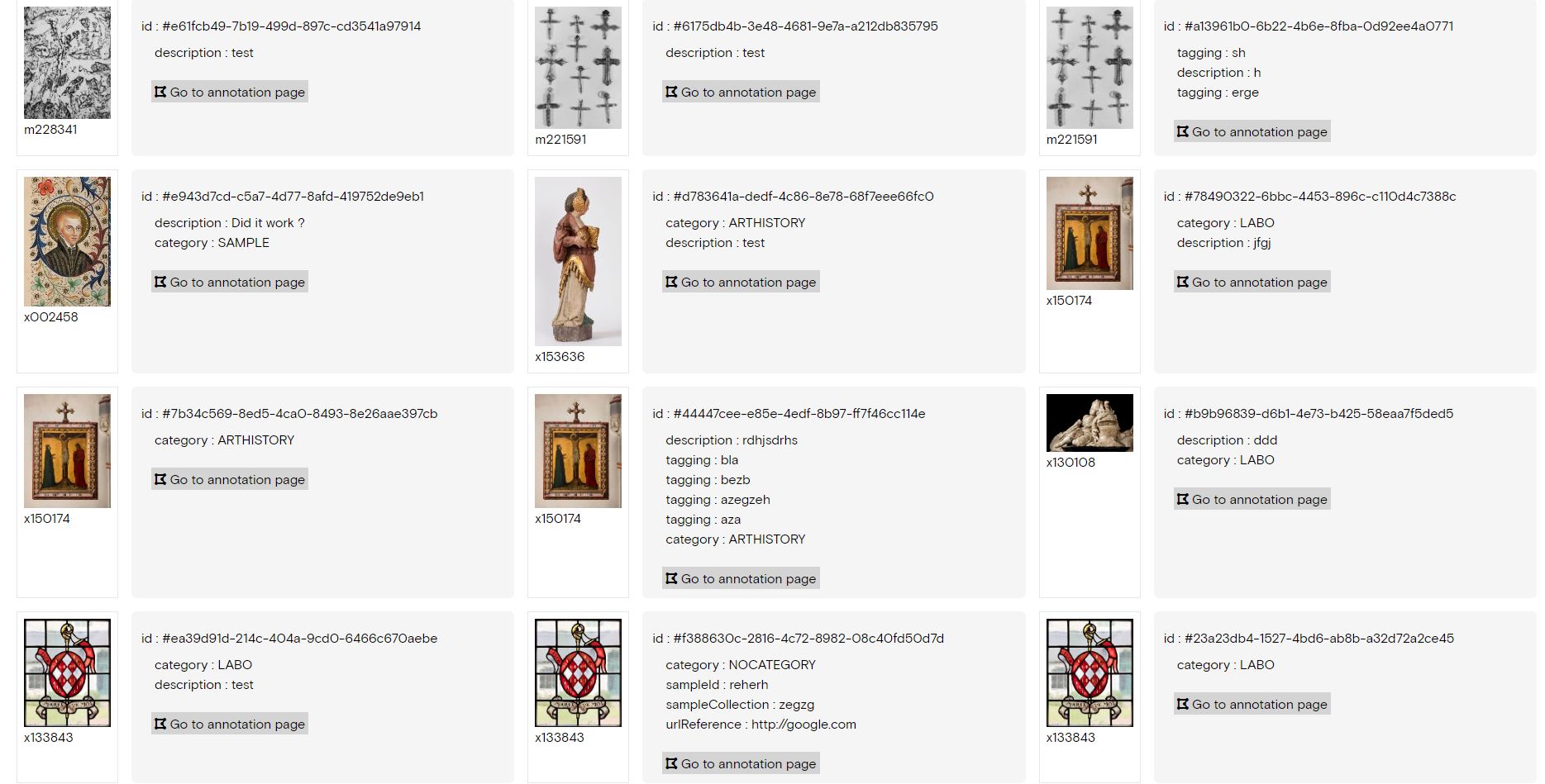
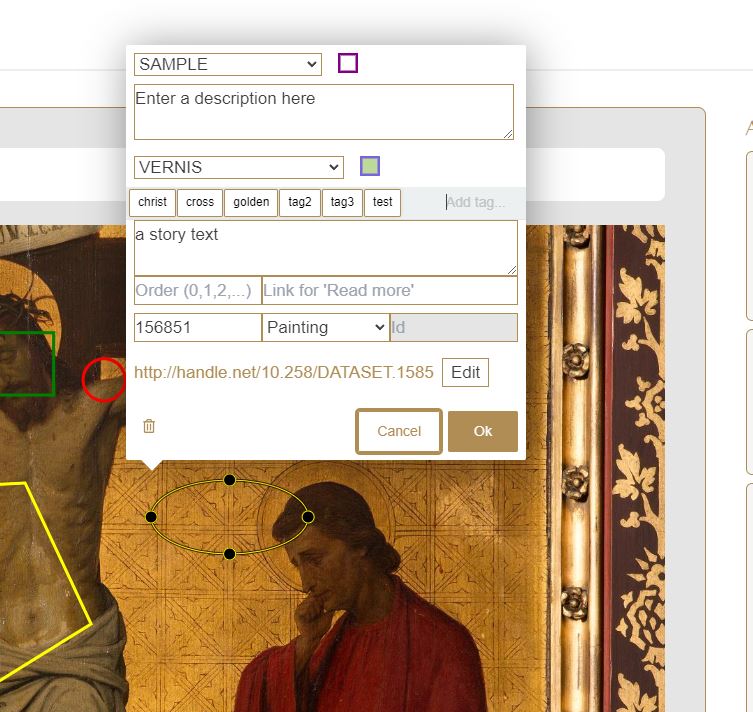
Annotations
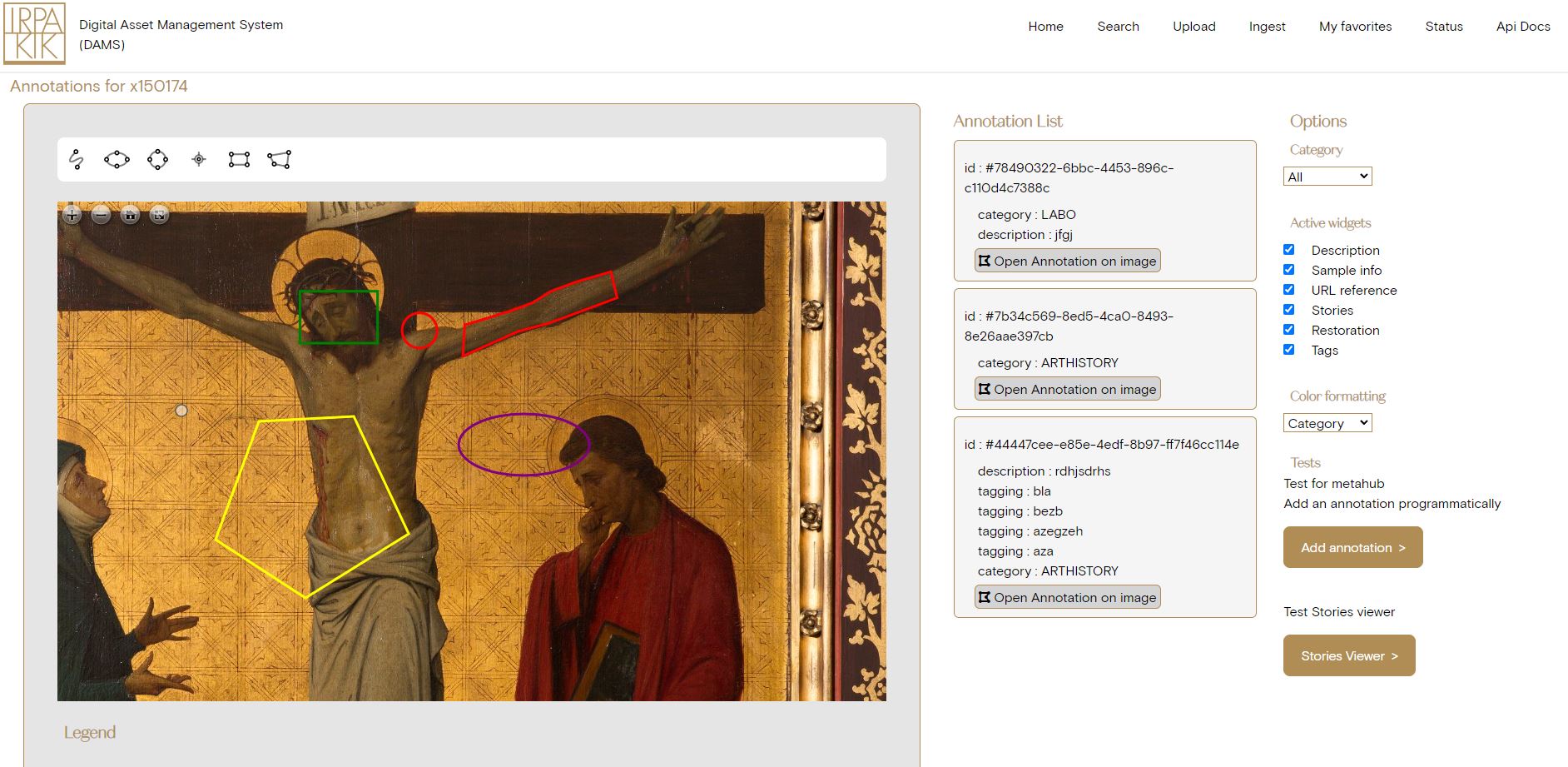
Linking our assets to specific references (like intervention files, objects, samples, …) is very useful, but we would like to go a step further and introduce annotation functionality to our entire collection. Using Annotorious + openseadragonJS , we have built an annotation workspace with filters and custom widgets for our high-resolution images. These widgets allow us to have annotations that serve different purposes: descriptive, tagging with keywords, link to URLs, stories, sample information, restoration technical information, … the possibilities are endless. This will allow us to link several types of information not only to the image, but to specific parts of the image.
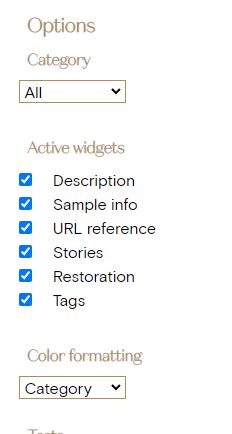
Visually we can create color schemes to display the annotations with a different look according to specific information saved in the annotations. Currently there are 2 schemes available, color by type of annotation (default) or color by restoration information (varnish, types of damage, …)
Viewers
An entire collection of images would of course be quite useless if we wouldn’t have tools to view them. All assets can be viewed with a high resolution web viewer thanks to our IIIF image server underneath, but we have added a “Compare viewer” and a “Story viewer” for maximum utility and research options.
By adding images to your favorites list, you can select any images from this list and open them together inside the “Compare viewer” to compare them at the same time while being able to zoom in and out. There are several modes:
- Sync mode will zoom and move all images in the same manner, this works best if the images are aligned and different modalities of the same object.
- Curtain mode will show the different images based on where the cursor currently is
- Independent mode allows you to zoom and move each image separately and independently
The “Story viewer”, uses the annotations made on an image that are of the type “story” and creates a walkthrough through an image, jumping from one spot to another with an explanation box.






Sharing and security
The DAMS will be the central point where permissions are managed for the assets, whether they are publicly available or not. Sharing of images can be done by either offering download options or sharing a link to an on-the-fly generated IIIF manifest, which can be used by other IIIF-compatible viewers to load images from our collection.
Technology
In line with most other software developed within the HESCIDA project, the DAMS is also made with the Python framework: FASTAPI, with MONGODB as the backend NoSQL database. An API is available to be able to integrate most functionality into our other HESCIDA projects and the front-end is made with Tailwind, JavaScript and JINJA2 templates built-in FASTAPI. Annotorious was used as a base for the annotation functionality due to its flexibility and customization and active support/development, it uses the W3C Web Annotation model.
With the DAMS, images are converted into pyramidal tifs using NIPS through PyVips in Python and stored on our image server (Linux, 65 TB) which uses Cantaloupe IIIF to serve our high-resolution images following IIIF standards.